
Table of Contents
Introduction
In this guide, you will discover how to create an intelligent agent using reinforcement learning without relying on a heuristic.
Rather than using a fixed strategy, we will continuously improve the agent’s performance by playing the game and aiming to increase the winning rate.
Throughout this manual, we may not delve deeply into this intricate subject, but you will grasp the overall concept and have the opportunity to examine code that will assist you in training your personal agent.
reinforcement learning vs supervised learning
reinforcement learning algorithms
reinforcement learning for trading
reinforcement learning in finance
reinforcement learning project
reinforcement learning definition
supervised unsupervised and reinforcement learning
Neural Networks
It can be quite challenging to develop a flawless heuristic. Enhancing the heuristic usually involves playing the game multiple times to identify certain scenarios where the agent could have made superior decisions.
It can also be tough to pinpoint the exact issues and rectify past errors without unintentionally creating new ones.
Wouldn’t it be simpler if we had a more structured approach to enhancing the agent through gameplay practice?
In this guide, we will work towards this objective by substituting the heuristic with a neural network.
The network takes the current board as input and generates a probability for each potential move.
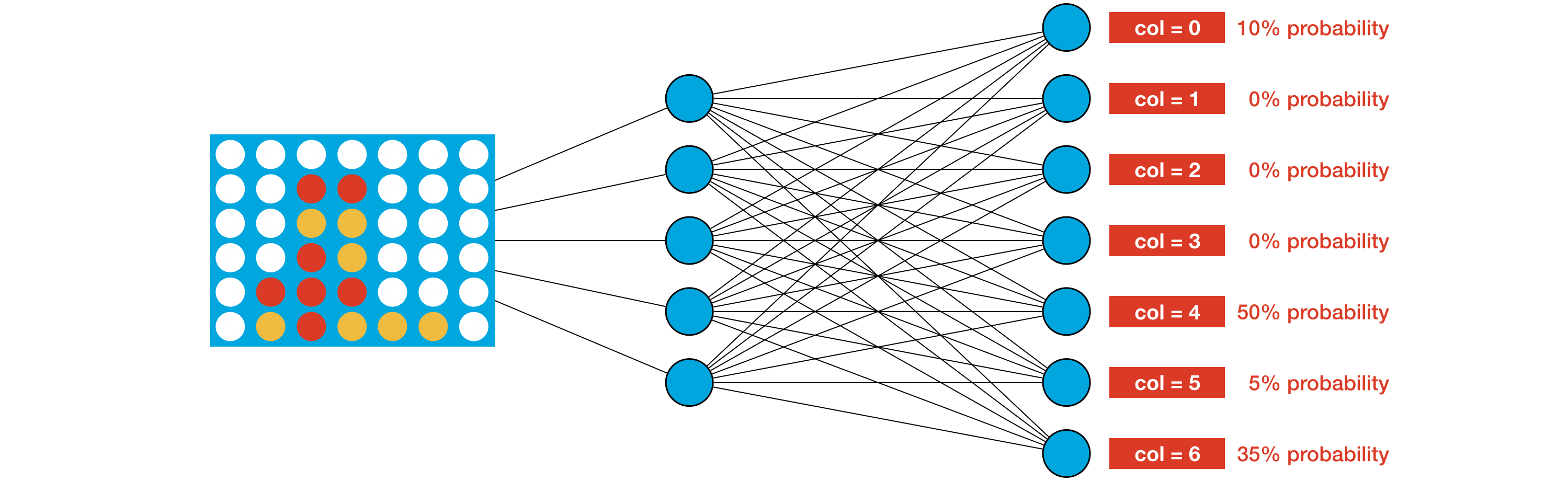
In order to choose its next move, the agent randomly picks a move based on these probabilities. For example, in the game board shown in the image, the agent has a 50% chance of selecting column 4.
By adjusting the weights of the network, we can effectively program a successful gameplay strategy. The idea is to assign higher probabilities to stronger moves for every potential game board.
However, in reality, we won’t be able to verify if this is always true. This is because Connect Four has an astonishing number of over 4 trillion possible game boards!
reinforcement learning online
reinforcement learning example
reinforcement learning methods
reinforcement learning conferences
reinforcement learning python tutorial
reinforcement learning vs unsupervised learning
Setup
In practice, we can adjust the weights of the network by following this approach:
After each move, the agent receives a reward based on its performance:
- If the agent wins the game, it gets a reward of +1.
- If the agent makes an invalid move, resulting in the game ending, it receives a reward of -10.
- If the opponent wins the game, the agent gets a reward of -1.
- Otherwise, the agent receives a reward of 1/42.
The agent calculates its cumulative reward by adding up the rewards at the end of each game.
Our objective is to optimize the weights of the neural network to maximize the agent’s cumulative reward, which is a fundamental concept in reinforcement learning. By defining the problem in this manner, we can apply various reinforcement learning algorithms to train the agent effectively.
Reinforcement Learning
In the next section, we’ll use the Proximal Policy Optimization (PPO) algorithm to create an agent.
What is Reinforcement Learning?
Let’s say you’re teaching your furry friend to fetch a ball. Every time your dog brings the ball back to you, you reward it with a treat.
However, if your dog doesn’t bring the ball back, it doesn’t receive any treat. As time goes by, your clever pup realizes that fetching the ball results in a reward, so it starts doing it more frequently.
machine learning reinforcement learning
reinforcement learning ai
reinforcement learning in artificial intelligence
reinforcement learning python
reinforcement learning course
reinforcement learning tutorial
Reinforcement Learning (RL) operates on a similar principle. It’s a type of machine learning where an “agent” (just like your dog) learns to make decisions by interacting with an environment in order to achieve a specific goal. Here’s a breakdown of the key concepts:
- Agent: This refers to the learner or decision-maker, similar to your dog.
- Environment: It encompasses everything that the agent interacts with, like your backyard.
- Actions: These are the choices that the agent can make, such as running to fetch the ball or ignoring it.
- States: These are the different situations that the agent can find itself in, like “ball is thrown,” “ball is nearby,” “ball is fetched,” and so on.
- Reward: It’s the feedback that the environment provides based on the action taken. In this case, the treat serves as the reward.
- Policy: This refers to the strategy that the agent follows to determine which action to take in each state, similar to how your dog thinks about fetching the ball to receive the treat.
- Value Function: It measures how good a particular state or action is in terms of future rewards. It assists the agent in deciding whether fetching the ball is a wise choice in the long run.
The ultimate goal of the agent is to learn a policy that maximizes the total reward over time. Just like your dog becomes better at fetching the ball with more practice, the agent enhances its actions by exploring different strategies and learning from the rewards it receives.
In a more technical scenario, imagine a robot learning to navigate through a maze. Every time it reaches the end successfully, it receives a positive reward.
However, if it bumps into a wall, it might receive a negative reward. The robot tries out various paths and gradually learns which actions lead to efficiently reaching the end of the maze. This is the essence of Reinforcement Learning!
Code
There are numerous high-quality implementations of reinforcement learning algorithms that can be found online. Throughout this course, we will utilize Stable-Baselines3.
In order to ensure compatibility with Stable-Baselines3, we must perform some additional setup. Specifically, we will create the ConnectFourGym class below. This class transforms ConnectX into an OpenAI Gym environment through various methods:
reset(): This method is called at the start of each game, providing a 2D numpy array with 6 rows and 7 columns representing the initial game board.change_reward(): Customizes the rewards received by the agent to align with our designed reward system, adjusting values to match the competition’s reward system for ranking agents.step(): Executes the agent’s selected action (action) and the opponent’s response, returning:- The resulting game board (as a numpy array).
- The agent’s reward from the most recent move (either +1, -10, -1, or 1/42).
- A boolean indicating if the game has concluded (
done=Trueif over; otherwise,done=False).
import random import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import gym from kaggle_environments import make, evaluate from gym import spaces class ConnectFourGym(gym.Env): def __init__(self, agent2="random"): ks_env = make("connectx", debug=True) self.env = ks_env.train([None, agent2]) self.rows = ks_env.configuration.rows self.columns = ks_env.configuration.columns # Learn about spaces here: http://gym.openai.com/docs/#spaces self.action_space = spaces.Discrete(self.columns) self.observation_space = spaces.Box(low=0, high=2, shape=(1,self.rows,self.columns), dtype=int) # Tuple corresponding to the min and max possible rewards self.reward_range = (-10, 1) # StableBaselines throws error if these are not defined self.spec = None self.metadata = None def reset(self): self.obs = self.env.reset() return np.array(self.obs['board']).reshape(1,self.rows,self.columns) def change_reward(self, old_reward, done): if old_reward == 1: # The agent won the game return 1 elif done: # The opponent won the game return -1 else: # Reward 1/42 return 1/(self.rows*self.columns) def step(self, action): # Check if agent's move is valid is_valid = (self.obs['board'][int(action)] == 0) if is_valid: # Play the move self.obs, old_reward, done, _ = self.env.step(int(action)) reward = self.change_reward(old_reward, done) else: # End the game and penalize agent reward, done, _ = -10, True, {} return np.array(self.obs['board']).reshape(1,self.rows,self.columns), reward, done, _
Loading environment lux_ai_s2 failed: No module named 'vec_noise'
Now, we’ll train an agent to beat the random agent. We specify this opponent in the agent2 argument below.
# Create ConnectFour environment env = ConnectFourGym(agent2="random")
To proceed, we need to establish the structure of the neural network. To achieve this, we will utilize a convolutional neural network (CNN).
If you require more information on how to define architectures using Stable-Baselines3, you can refer to the documentation provided here.
The neural network we are using will generate probabilities for selecting each column. Additionally, since we are implementing the PPO algorithm (as demonstrated in the code cell below), our network will also provide supplementary information known as the “value” of the input.
Although this concept is not covered in this course, you can delve deeper into it by exploring “actor-critic networks.”
import torch as th import torch.nn as nn !pip install "stable-baselines3" from stable_baselines3 import PPO from stable_baselines3.common.torch_layers import BaseFeaturesExtractor # Neural network for predicting action values class CustomCNN(BaseFeaturesExtractor): def __init__(self, observation_space: gym.spaces.Box, features_dim: int=128): super(CustomCNN, self).__init__(observation_space, features_dim) # CxHxW images (channels first) n_input_channels = observation_space.shape[0] self.cnn = nn.Sequential( nn.Conv2d(n_input_channels, 32, kernel_size=3, stride=1, padding=0), nn.ReLU(), nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=0), nn.ReLU(), nn.Flatten(), ) # Compute shape by doing one forward pass with th.no_grad(): n_flatten = self.cnn( th.as_tensor(observation_space.sample()[None]).float() ).shape[1] self.linear = nn.Sequential(nn.Linear(n_flatten, features_dim), nn.ReLU()) def forward(self, observations: th.Tensor) -> th.Tensor: return self.linear(self.cnn(observations)) policy_kwargs = dict( features_extractor_class=CustomCNN, ) # Initialize agent model = PPO("CnnPolicy", env, policy_kwargs=policy_kwargs, verbose=0)
In the code cell above, the weights of the neural network are initially set to random values.
In the next code cell, we “train the agent”, which is just another way of saying that we find weights of the neural network that are likely to result in the agent selecting good moves.
# Train agent model.learn(total_timesteps=60000)
<stable_baselines3.ppo.ppo.PPO at 0x7b40a1c1b250>
Finally, we specify the trained agent in the format required for the competition.
def agent1(obs, config): # Use the best model to select a column col, _ = model.predict(np.array(obs['board']).reshape(1, 6,7)) # Check if selected column is valid is_valid = (obs['board'][int(col)] == 0) # If not valid, select random move. if is_valid: return int(col) else: return random.choice([col for col in range(config.columns) if obs.board[int(col)] == 0])
In the next code cell, we see the outcome of one game round against a random agent.
# Create the game environment env = make("connectx") # Two random agents play one game round env.run([agent1, "random"]) # Show the game env.render(mode="ipython")
And, we calculate how it performs on average, against the random agent.
get_win_percentages(agent1=agent1, agent2="random")
Agent 1 Win Percentage: 0.68 Agent 2 Win Percentage: 0.32 Number of Invalid Plays by Agent 1: 0 Number of Invalid Plays by Agent 2: 0
It’s worth mentioning that the agent we’ve developed was specifically trained to defeat a random opponent. All of its gameplay experience has been against this particular type of adversary.
In order to create an agent that consistently surpasses a wide range of opponents, we must train it against a diverse array of adversaries.
reinforcement learning course online
q learning tutorial
What is the difference between ML and RL?
Machine Learning (ML) and Reinforcement Learning (RL) are two distinct subfields of artificial intelligence that have different focuses, approaches, and applications. Let’s take a closer look at each:
Machine Learning (ML)
Explanation
Machine Learning is a branch of study that concentrates on developing algorithms that enable computers to learn from data and make predictions or decisions. It encompasses a wide range of techniques and methods.
Types of ML
- Supervised Learning: In this type, the algorithm learns from labeled data, where each training example has input-output pairs. The objective is to learn a mapping from inputs to outputs. Examples: Classification tasks like spam detection, Regression tasks like house price prediction.
- Unsupervised Learning: This type involves learning from unlabeled data to discover hidden patterns or structures within the input data. Examples: Clustering tasks like customer segmentation, Dimensionality Reduction tasks like PCA.
- Semi-Supervised Learning: This approach combines both labeled and unlabeled data to enhance learning accuracy.
- Self-Supervised Learning: In this method, the model generates its own labels from the input data. It is commonly used in natural language processing and computer vision.
- Transfer Learning: Transfer learning involves applying knowledge gained while solving one problem to a different but related problem.
What is the basic reinforcement learning?
Explanation
Reinforcement Learning is a specific type of machine learning where an agent learns to make decisions by taking actions and receiving rewards or penalties in response. It focuses on learning sequences of actions to achieve long-term goals.
Key Components
- Agent: The individual making decisions or learning.
- Environment: The external system where the agent operates.
- State: Representation of the current situation of the agent.
- Action: All possible moves the agent can take.
- Reward: Feedback received from the environment after an action is taken.
Key Concepts
- Policy: Strategy guiding the agent’s actions in each state.
- Value Function: Estimation of expected reward for a state or state-action pair.
- Model of the Environment: Agent’s understanding of how the environment behaves.
Types of RL
- Model-Free RL: Agent learns the policy without a model of the environment.
Examples: Q-Learning, Deep Q-Network (DQN). - Model-Based RL: Agent constructs a model of the environment to plan actions.
Examples: Dyna-Q, AlphaGo.
reinforcement learning algorithms
reinforcement learning algorithm
algorithm for reinforcement learning
algorithms for reinforcement learning
reinforced learning algorithms
reinforcement learning ai
reinforcement learning in ai
ai reinforcement learning
Differences
| Aspect | Machine Learning (ML) | Reinforcement Learning (RL) |
|---|---|---|
| Learning Paradigm | Often uses fixed datasets for training (batch learning). | Interacts continuously with the environment and learns from ongoing interactions (online learning). |
| Feedback Type | Direct feedback (labels or ground truth). | Indirect feedback (rewards), which may be delayed. |
| Objective | Aims to minimize prediction error on a given dataset. | Aims to maximize cumulative reward through a sequence of actions. |
| Applications | Image recognition, speech recognition, recommendation systems, fraud detection, etc. | Game playing (e.g., AlphaGo), robotics, autonomous driving, resource management, etc. |
In conclusion, while ML focuses on pattern recognition and prediction from data, RL is specifically about learning optimal actions through trial and error to maximize rewards in dynamic environments.
reinforcement learning artificial intelligence
artificial intelligence reinforcement learning
reinforcement learning in artificial intelligence
reinforcement machine learning
machine learning reinforcement learning
reinforced learning machine learning
reinforcement learning in machine learning
reinforcement learning python
Is an example of reinforcement learning?
Imagine you’re training a new puppy. You want it to learn some tricks, but you don’t tell it exactly what to do. Instead, you let it explore and try things out. Here’s how it might go:
- The puppy (like an AI agent) is in an environment (your house).
- The puppy tries different actions (like barking, jumping, chewing).
- You give the puppy rewards (treats, praise) for good actions (sitting, fetching). You might give it a timeout (like taking away a toy) for bad actions (chewing furniture).
- Over time, the puppy learns which actions lead to treats and praise, and avoids things that get it in trouble. This shapes its future behavior.
Playing chess with a pre-programmed strategy isn’t like training a puppy. The chess program already knows all the moves and strategies. It’s like having a giant instruction booklet for chess!
reinforcement learning in python
reinforcement learning with human feedback
reinforcement learning sutton
sutton reinforcement learning
reinforcement learning course
reinforcement learning class
reinforcement learning classes
reinforcement learning courses
reinforcement learning applications
reinforcement learning tutorial
reinforcement learning tutorials
Here’s an example that’s more like training a puppy:
Imagine a robot is learning to balance a pole. It doesn’t have instructions. It just tries moving left and right (like the puppy trying different actions). If it keeps the pole balanced (gets a reward!), it learns to do more of those movements. If the pole falls (like the puppy getting in trouble), it learns to avoid those movements. Over time, through trial and error, the robot learns to balance the pole by itself!
import gym
import numpy as np
# This line defines the environment (balancing the pole)
env = gym.make('CartPole-v1')
# These lines set parameters for learning (like how much the robot learns from each try)
alpha = 0.1 # Learning rate
gamma = 0.9 # Discount factor
# This line creates a table to store what the robot has learned about different situations (states) and actions
Q = np.zeros((env.observation_space.n, env.action_space.n))
# This sets the number of times the robot will try to balance the pole
episodes = 1000
# This loop runs the training process
for episode in range(episodes):
# This line resets the environment for each attempt
state = env.reset()
# This loop keeps running until the pole falls
while True:
# This part (to be filled in) would use the Q-table to decide which action to take (left or right)
# ... (code to select action based on Q-values)
# This line takes the action, observes the outcome, and gets a reward
next_state, reward, done, _ = env.step(action)
# This part (to be filled in) would update the Q-table based on the reward and what the robot learned
# ... (code to update Q-value using reward, next state, etc.)
# This line moves the robot to the next situation
state = next_state
# This line checks if the pole fell (game over)
if done:
break
# This line closes the environment
env.close()That’s the core idea behind reinforcement learning. Just like the puppy learning tricks, the agent learns by interacting with its environment and getting feedback.
reinforcement learning in trading
reinforcement learning trade
reinforcement learning human feedback
reinforcement learning projects
reinforcement learning project
reinforcement learning definition
supervised unsupervised and reinforcement learning
reinforcement learning online
reinforcement learning example
reinforcement learning methods
reinforcement learning conferences
What are the three main types of reinforcement learning?
The Thoughtful Pup: This pup is like a little philosopher. It carefully analyzes the situation, creating a mental map to anticipate outcomes.
It then selects the action that is most likely to result in a positive outcome, such as a delicious treat! While effective in straightforward scenarios, it may struggle in more complex environments.
The Energetic Pup: This pup learns through active engagement. It eagerly explores its surroundings, remembering successful strategies.
Picture it figuring out the path to treats through trial and error. While versatile in various situations, it may require additional time to play around and discover solutions.
The Strategic Pup: This pup excels in strategic thinking. It evaluates different locations based on the rewards they offer, assigning value accordingly.
For example, it may learn that sniffing near the fridge often leads to treats, making it a preferred spot. By utilizing this value system, the pup makes decisions that maximize long-term rewards.
reinforcement learning python tutorial
reinforcement learning vs unsupervised learning
reinforcement learning course online
q learning tutorial
Conclusion
During this lesson about reinforcement learning, we delved into different facets of this domain. We covered topics like algorithms, applications in artificial intelligence and finance, and how it connects with other machine learning methods.
Additionally, we provided information on additional resources for further learning, like courses and tutorials. At this point, you should have a strong grasp of the basics of reinforcement learning and its possibilities.
Learn more




5 Comments
Lot Balonem Voucher · July 8, 2024 at 10:08 am
What a fantastic read! Your ability to present ideas in a clear and concise manner is impressive. This post not only provided great insights but also sparked some new ideas for me. Thank you for putting in the effort to share this!
Ile Kosztuje Lot Balonem · July 8, 2024 at 10:34 pm
You have an amazing way with words. This article was as informative as it was beautifully written.
Lesson 3: Best Transformers And BERT Tutorial With DL/NLP · June 2, 2024 at 2:59 pm
[…] Lesson 4: Best Deep Reinforcement Learning Course […]
Lesson 2: Best Pytorch Tutorial For Deep Learning · June 2, 2024 at 3:00 pm
[…] Lesson 4: Best Deep Reinforcement Learning Course […]
Best Deep Learning Tutorial For Beginners With Python 2024 · June 2, 2024 at 3:01 pm
[…] Lesson 4: Best Deep Reinforcement Learning Course […]